Whisper-Medusa是什么
Whisper-Medusa是aiOla推出的开源AI语音识别模型,结合了OpenAI的Whisper技术与aiOla的创新,Whisper-Medusa引入了多头注意力机制,实现了并行处理,显著提升了推理速度,平均提速达到50%。模型专为英语优化,支持超过100种语言,适用于翻译、金融、旅游等多个行业。Whisper-Medusa在LibriSpeech数据集上训练,有出色的性能和准确度,通过弱监督方法和训练技巧,减少了对大量手动标注数据的依赖。aiOla计划进一步扩展模型的多头注意力机制,以实现更高的效率。

Whisper-Medusa的主要功能
高速语音识别:通过多头注意力机制,Whisper-Medusa能够并行处理语音数据,实现比传统模型快50%的转录速度。高准确度:尽管速度提升,但Whisper-Medusa在语音识别的准确度上与原始Whisper模型相当,保持了高准确度。多语言支持:模型支持超过100种语言的转录和翻译,适用于多种语言环境。弱监督训练:Whisper-Medusa使用弱监督方法进行训练,减少了对大量手动标注数据的依赖。适应性强:模型能够理解特定行业的术语和口音,适用于不同声学环境。Whisper-Medusa的技术原理
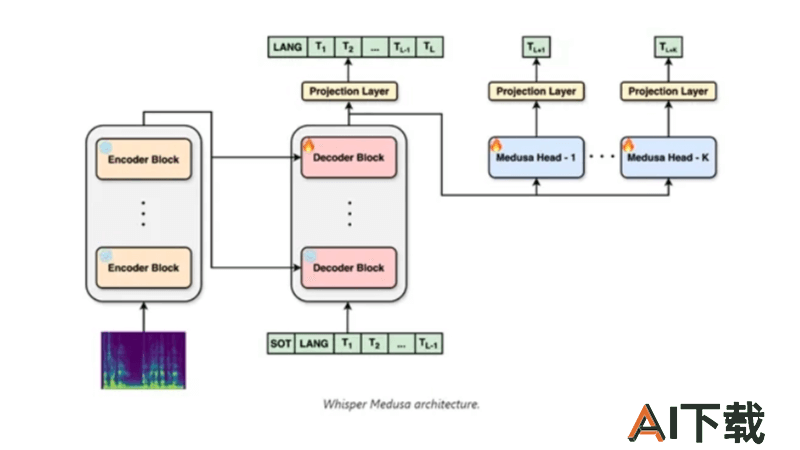
多头注意力机制:与传统的Transformer模型不同,Whisper-Medusa采用了多头注意力机制,允许模型同时处理多个数据单元(tokens)。这种并行化处理显著提高了模型的推理速度。弱监督训练:在训练过程中,Whisper-Medusa采用了弱监督方法。这意味着在训练初期,原始Whisper模型的主要组件被冻结,同时训练额外的参数。使用由Whisper生成的音频转录作为伪标签,来训练Medusa的额外token预测模块。并行计算:模型的每个”头”可以独立地计算注意力分布,然后并行地处理输入数据。这种并行化方法不仅加快了推理速度,还增加了模型的表达能力,因为每个头都可以专注于序列的不同部分,捕捉更丰富的上下文信息。优化的损失函数:在训练过程中,损失函数需要同时考虑预测的准确性和效率。模型被鼓励在保证精度的前提下,尽可能地加快预测速度。稳定性和泛化能力:为了确保模型在训练过程中稳定收敛并避免过拟合,aiOla采用了学习率调度、梯度裁剪、正则化等多种方法。