SEED-Story是什么
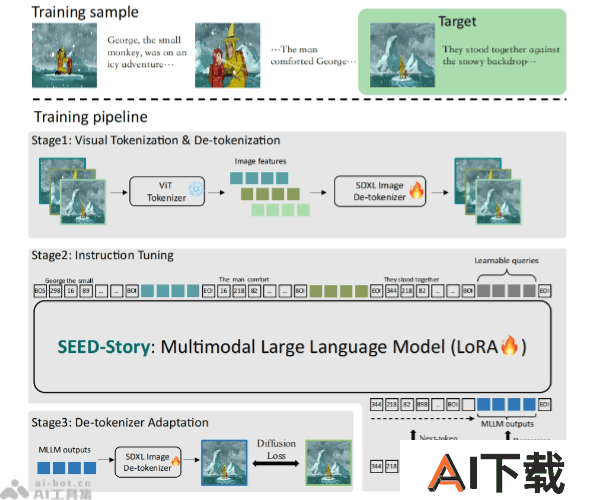
SEED-Story是腾讯联合香港科技大学、香港中文大学推出的多模态故事生成模型。基于多模态大语言模型(MLLM),能预测文本和视觉token,通过视觉de-tokenizer生成风格一致的图像。SEED-Story引入了多模态注意力机制,支持生成长达25个序列的连贯故事。SEED-Story还提供了StoryStream,一个大规模高分辨率数据集,用于模型训练和评估。

SEED-Story的主要功能
多模态故事生成:SEED-Story 能根据给定的起始图像和文本生成包含连贯叙事文本和风格一致的图像的长故事。多模态注意力汇聚机制:SEED-Story 提出了一种多模态注意力汇聚机制,以高效自回归的方式生成故事,可以生成长达25序列的故事。大规模数据集 :SEED-Story 发布了一个名为 StoryStream 的大规模、高分辨率数据集,用于训练模型并从不同方面定量评估多模态故事生成任务。故事指令调整:在故事生成的过程中,SEED-Story 通过指令调整过程,对模型进行微调,可以预测故事的下一个图像和下一句文本。可视化和交互:SEED-Story 还提供了可视化比较,展示了生成的图像与其他基线模型相比具有更高的质量和更好的一致性。SEED-Story的技术原理
多模态大语言模型(MLLM):利用大型语言模型来理解、生成和预测文本和视觉标记。这种模型能够处理和生成文本数据,同时理解和生成视觉内容。文本和视觉标记预测:SEED-Story模型能够预测文本标记(文本中的元素或单词)和视觉标记(图像中的元素)。视觉de-tokenizer:将语言模型生成的文本和视觉标记转换为图像,通过视觉de-tokenizer生成具有一致性和风格的图像。多模态注意力机制:引入多模态注意力机制,使模型在生成故事时能够关注文本和图像之间的相互关系。这种机制允许模型更有效地处理长序列的生成任务。自回归生成:模型采用自回归方式生成故事,即每个新生成的标记依赖于之前生成的所有标记,以保持故事的连贯性。长序列生成能力:通过多模态注意力机制,SEED-Story能够生成比训练序列更长的故事序列。StoryStream数据集:提供一个大规模的高分辨率数据集,用于训练模型并评估多模态故事生成任务。数据集包含视觉上引人入胜的高分辨率图像和详细的叙述文本。训练流程:包括预训练去标记器以重建图像,采样交错图像文本序列进行训练,以及使用MLLM的回归图像特征来调整生成的图像。