EmoTalk3D是什么
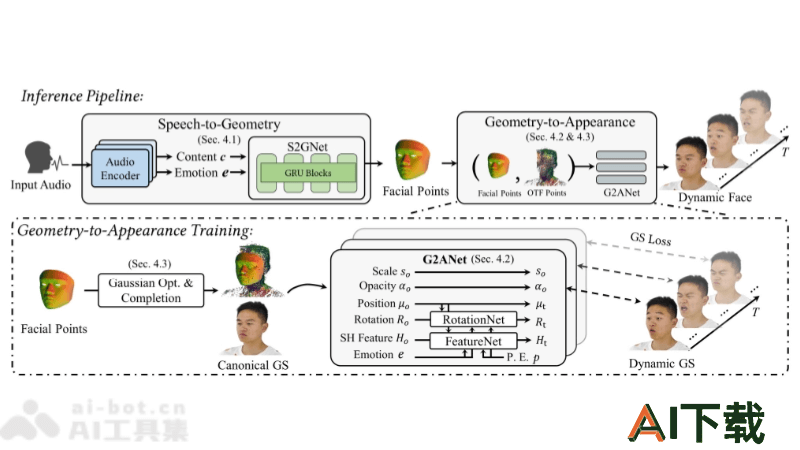
EmoTalk3D是华为诺亚方舟实验室、南京大学和复旦大学共同推出的3D数字人框架。技术的核心在于能合成具有丰富情感表达的3D会说话头像。EmoTalk3D能捕捉和再现人类在说话时的唇部动作、面部表情,甚至是更微妙的情感细节,如皱纹和其他面部微动。EmoTalk3D通过一个名为“Speech-to-Geometry-to-Appearance”的映射框架,实现了从音频特征到3D几何序列的预测,再到3D头像外观的合成。

EmoTalk3D的主要功能
情感表达合成:能根据输入的音频信号合成具有相应情感表达的3D头像动画,包括不限于喜悦、悲伤、愤怒等多种情感状态。唇部同步:高度准确的唇部运动与语音同步,3D头像在说话时唇部动作与实际发音相匹配。多视角渲染:支持从不同角度渲染3D头像,确保在不同视角下观看时都能保持高质量和一致性。动态细节捕捉:能捕捉并再现说话时的面部微表情和动态细节,如皱纹、微妙的表情变化等。可控情感渲染:用户可根据需要控制3D头像的情感表达,实现情感的实时调整和控制。高保真度:通过先进的渲染技术,EmoTalk3D能生成高分辨率、高真实感的3D头像。EmoTalk3D的技术原理
数据集建立(EmoTalk3D Dataset):收集了多视角视频数据,包括情感标注和每帧的3D面部几何信息。数据集来源于多个受试者,每个受试者在不同情感状态下录制了多视角视频。音频特征提取:使用预训练的HuBERT模型作为音频编码器,将输入语音转换为音频特征。通过情感提取器从音频特征中提取情感标签。Speech-to-Geometry Network (S2GNet):将音频特征和情感标签作为输入,预测动态的3D点云序列。基于门控循环单元(GRU)作为核心架构,生成4D网格序列。3D几何到外观的映射(Geometry-to-Appearance):基于预测的4D点云,使用Geometry-to-Appearance Network (G2ANet)合成3D头像的外观。将外观分解为规范高斯(静态外观)和动态高斯(由面部运动引起的皱纹、阴影等)。4D高斯模型:使用3D高斯Splatting技术来表示3D头像的外观。每个3D高斯由位置、尺度、旋转和透明度等参数化表示。动态细节合成:通过FeatureNet和RotationNet网络预测动态细节,如皱纹和微妙的表情变化。头部完整性:对于非面部区域(如头发、颈部和肩部),使用优化算法从均匀分布的点开始构建。渲染模块:将动态高斯和规范高斯融合,渲染出具有自由视角的3D头像动画。情感控制:通过情感标签的人工设置和时间序列的变化,控制生成头像的情感表达。