Qwen2-Audio是什么
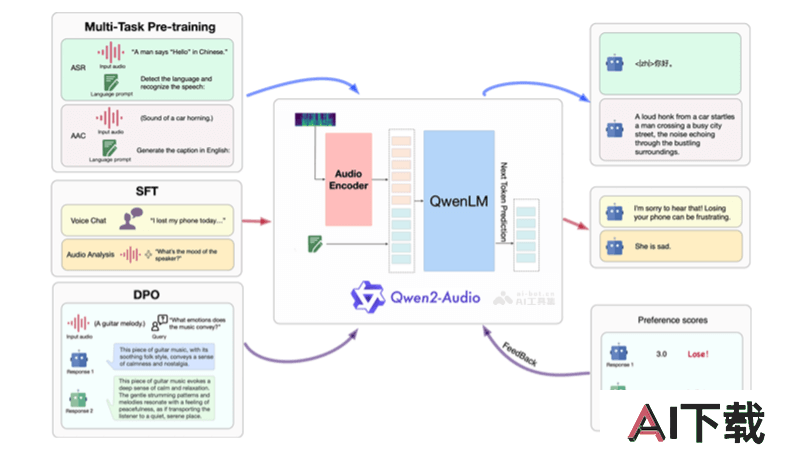
Qwen2-Audio是阿里通义千问团队最新推出的开源AI语音模型,支持直接语音输入和多语言文本输出。具备语音聊天、音频分析功能,支持超过8种语言。Qwen2-Audio在多个基准数据集上表现优异,现已集成至Hugging Face的transformers库,方便开发者使用。模型还支持通过ms-swift框架进行微调,适应特定应用场景。

Qwen2-Audio的主要功能
语音聊天:用户可以直接用语音与模型交流,无需通过ASR转换。音频分析:能根据文本指令分析音频内容,识别语音、声音和音乐等。多语言支持:支持中文、英语、粤语、法语等多种语言和方言。高性能:在多个基准数据集上超越先前模型,表现出色。易于集成:代码已集成到Hugging Face的transformers库,方便开发者使用和推理。可微调性:支持通过ms-swift框架进行模型微调,适应不同应用需求。Qwen2-Audio的技术原理
多模态输入处理:Qwen2-Audio模型能接收并处理音频和文本两种模态的输入。音频输入通常通过特征提取器转换成模型能够理解的数值特征。预训练与微调:模型在大量多模态数据上进行预训练,学习语言和音频的联合表示。微调则是在特定任务或领域数据上进一步训练模型,提高其在特定应用场景下的性能。注意力机制:模型使用注意力机制来加强音频和文本之间的关联,在生成文本时能考虑到音频内容的相关信息。条件文本生成:Qwen2-Audio支持条件文本生成,即模型可以根据给定的音频和文本条件生成相应的响应文本。编码器-解码器架构:模型采用编码器-解码器架构,其中编码器处理输入的音频和文本,解码器生成输出文本。Transformer架构:作为transformers库的一部分,Qwen2-Audio采用了Transformer架构,这是一种常用于处理序列数据的深度学习模型,适用于自然语言处理任务。优化算法:在训练过程中,使用优化算法(如Adam)来调整模型参数,最小化损失函数,提高模型的预测准确性。