ReSyncer是什么
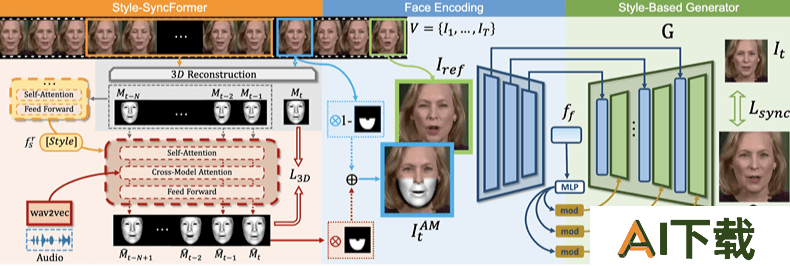
ReSyncer是清华大学和百度联合推出的AI视频编辑工具,通过音频驱动生成与声音同步的高质量嘴唇动作视频。ReSyncer用Style-SyncFormer分析声音并创建3D面部模型,结合目标视频生成同步且表情丰富的虚拟人物。ReSyncer支持个性化微调、说话风格转换和换脸功能,适用于虚拟主持人、表演者创作及实时直播等场景,在视听面部信息同步方面的效果卓越。

ReSyncer的主要功能
口型同步:根据给定的音频生成与声音同步的嘴唇动作。风格迁移:将特定的说话风格或面部表情迁移到目标视频中。个性化微调:快速调整生成的面部动画以匹配特定人物的面部特征。视频驱动的口型同步:使用目标视频的面部图像来驱动口型动画。换脸技术:将一个人的面部特征替换为另一个人的,用于身份转换或特效制作。ReSyncer的技术原理
3D面部模型生成:使用Style-SyncFormer,一个深度学习模型,根据声音特征预测3D面部动态。风格化面部动态:通过Transformer结构学习风格化的3D面部动态,实现面部表情和口型的精确同步。基于风格的生成器:将预测得到的3D面部动态与目标视频中的面部图像结合,生成高保真的面部图像。面部特征融合:在生成过程中,通过简单的插入机制将3D面部网格信息与风格化特征融合,提高嘴唇同步的质量和稳定性。