MagicPose是什么
MagicPose是南加州大学和字节跳动联合研发的AI视频生成模型,无需任何微调,直接生成逼真的人类动作和面部表情视频。MagicPose通过一个新颖的两阶段训练策略,分离人体动作和外观特征,实现了在不同身份间进行动作和表情的精确转移。MagicPose的另一大优势是它的易用性,可以作为Stable Diffusion等文本到图像模型的插件使用,且在多种复杂场景下展现出良好的泛化能力。

MagicPose的功能特色
逼真视频生成:能生成具有生动运动和面部表情的逼真人类视频。无需微调:MagicPose可直接在野外数据上生成一致性高的视频,无需针对特定数据进行微调。外观一致性:在生成视频时能够保持人物的外观特征,如面部特征、肤色和着装风格等。动作和表情转移:可以将一个人物的动作和表情转移到另一个人物上,同时保持目标人物的身份信息。MagicPose的技术原理
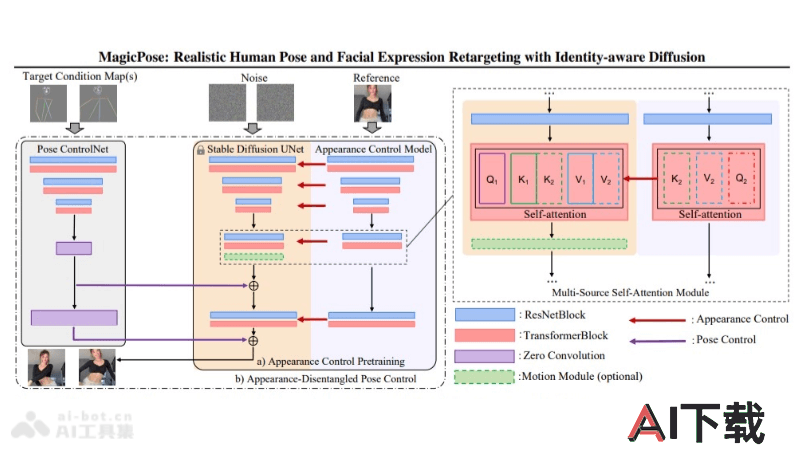
基于扩散的模型:MagicPose采用了一种基于扩散的模型,模型能处理2D人体动作和面部表情的转移。两阶段训练策略:包括两个阶段,第一阶段是预训练外观控制块,第二阶段是精细调整外观-姿势-联合控制块。外观控制模型:MagicPose使用外观控制模型来分离人体动作和外观特征,如面部表情、肤色和着装。多源自注意模块:外观控制预训练阶段,训练外观控制模型及其多源自注意模块,在不同姿态下保持一致的外观。外观解纠缠姿态控制:在第二阶段,联合微调外观控制模型和姿态控制网,实现外观和动作的精确控制。冻结训练模块:在训练过程中,一旦某些模块训练完成,就会冻结这些模块的权重,保持稳定性。AnimateDiff初始化:使用AnimateDiff初始化运动模块,进行微调,生成逼真的人体动作。泛化能力:MagicPose在训练后能够泛化到未见过的人类身份和复杂的运动序列上,无需额外的微调。