FancyVideo是什么
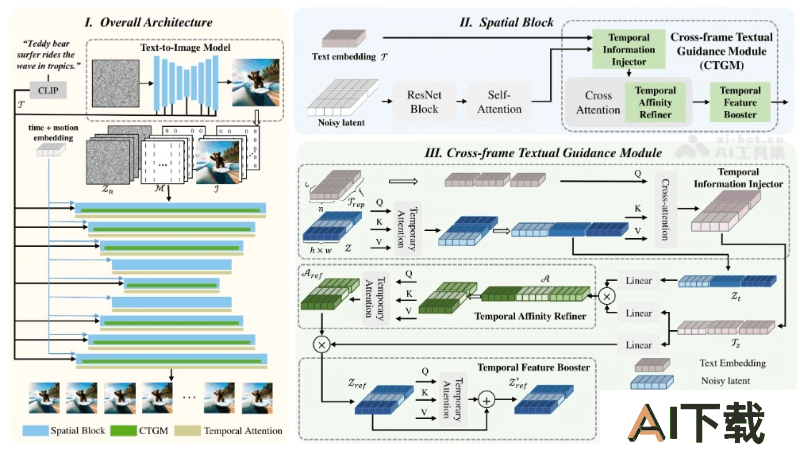
FancyVideo是360联合中山大学推出的AI文生视频模型。基于创新的跨帧文本引导模块(Cross-frame Textual Guidance Module, CTGM),能根据文本提示生成动态丰富且时间上连贯的视频内容。FancyVideo突破极大地提升了文本到视频(Text-to-Video, T2V)生成任务的质量和自然度。FancyVideo是开源的,有丰富的代码库和文档,便于研究者和开发者进一步探索和应用。FancyVideo的官网提供了直观的演示和使用指南,让非技术用户也能快速了解其功能和潜力。
FancyVideo的主要功能
文本到视频生成:用户只需提供文本描述,FancyVideo能生成视频内容,实现从文本到动态视觉的转换。跨帧文本引导:通过CTGM模块,模型能在不同帧之间进行动态调整,生成具有连贯性和逻辑性的视频。高分辨率视频输出:FancyVideo支持生成高分辨率的视频,满足高质量视频内容的需求。时间一致性保持:视频中的对象和动作能保持时间上的连贯性,生成的视频更加自然和逼真。FancyVideo的技术原理
文本到视频生成(Text-to-Video Generation):FancyVideo使用深度学习模型,特别是扩散模型,将文本描述转换成视频内容。跨帧文本引导(Cross-frame Textual Guidance):通过Cross-frame Textual Guidance Module(CTGM),能在视频的不同帧之间实现文本的连贯引导,确保视频内容在时间上的连贯性和动态性。时间信息注入(Temporal Information Injection):模型在生成每一帧时,注入与时间相关的信息,确保视频帧之间的过渡自然且符合文本描述的动态变化。时间亲和度细化(Temporal Affinity Refinement):使用Temporal Affinity Refiner(TAR)来优化帧特定文本嵌入与视频之间的时间维度相关性,增强文本引导的逻辑性。时间特征增强(Temporal Feature Boosting):Temporal Feature Booster(TFB)进一步提升潜在特征的时间一致性,确保视频在连续播放时的流畅性和稳定性。