DeepSeek-Prover-V1.5是什么
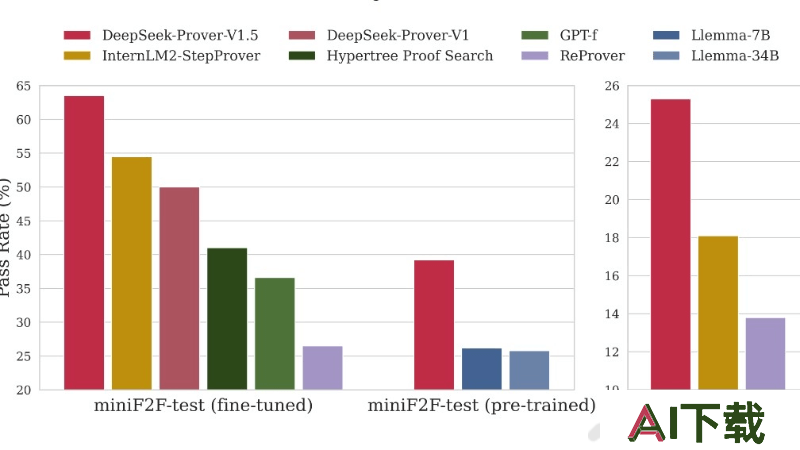
DeepSeek-Prover-V1.5是由DeepSeek团队开发的开源数学大模型,拥有70亿参数。模型通过结合强化学习(RLPAF)和蒙特卡洛树搜索(特别是RMaxTS变体),在数学定理证明方面取得了显著的效率和准确性提升。在高中和大学级别的数学问题上,DeepSeek-Prover-V1.5在Lean 4平台上的表现超越了其他所有开源模型,创造了新的最先进水平(SOTA)。不仅能验证现有证明,还有潜力帮助创造新的数学知识,推动数学研究进入“大数学”时代。

DeepSeek-Prover-V1.5的主要功能
强化学习优化:模型采用基于证明助手反馈的强化学习(RLPAF),通过Lean证明器的验证结果作为奖励信号,优化证明生成过程。蒙特卡洛树搜索:引入RMaxTS算法,一种蒙特卡洛树搜索的变体,用于解决证明搜索中的奖励稀疏问题,增强模型探索行为。证明生成能力:模型能生成高中和大学级别的数学定理证明,显著提高了证明的成功率。预训练与微调:在高质量数学和代码数据上进行预训练,并针对Lean 4代码补全数据集进行监督微调,提升了模型的形式化证明能力。自然语言与形式化证明对齐:用DeepSeek-Coder V2在Lean 4代码旁注释自然语言思维链,将自然语言推理与形式化定理证明相结合。DeepSeek-Prover-V1.5的技术原理
预训练(Pre-training):DeepSeek-Prover-V1.5在数学和代码数据上进行了进一步的预训练,专注于Lean、Isabelle和Metamath等形式化数学语言,以增强模型在形式化定理证明和数学推理方面的能力。监督微调(Supervised Fine-tuning):使用特定的数据增强技术,包括在Lean 4代码旁边添加自然语言的思维链注释,以及在证明代码中插入中间策略状态信息,以此来提高模型对自然语言和形式化证明之间一致性的理解。强化学习(Reinforcement Learning):采用GRPO算法进行基于证明助手反馈的强化学习,利用Lean证明器的验证结果作为奖励信号,进一步优化模型,使其与形式化验证系统的要求更加一致。蒙特卡洛树搜索(Monte-Carlo Tree Search, MCTS):引入了一种新的树搜索方法,通过截断和重新开始机制,将不完整的证明分解为树节点序列,并利用这些节点继续证明生成过程。内在奖励驱动的探索(Intrinsic Rewards for Exploration):通过RMaxTS算法,DeepSeek-Prover-V1.5使用内在奖励来驱动探索行为,鼓励模型生成多样化的证明路径,解决证明搜索中的奖励稀疏问题。