Seed-ASR是什么
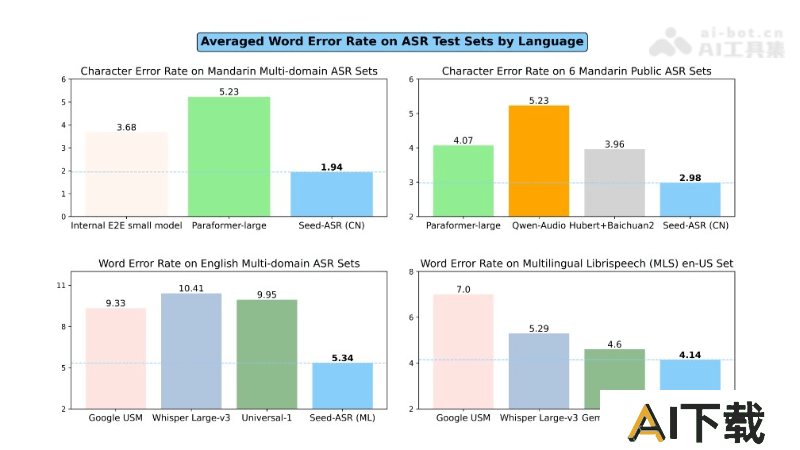
Seed-ASR是字节跳动推出的一款基于大型语言模型(LLM)的语音识别(ASR)模型。在超过2000万小时的语音数据和近90万小时的配对ASR数据上训练,支持普通话和13种中国方言的转录,能识别英语和其他7种外语的语音。Seed-ASR采用自监督学习、监督微调、上下文感知训练和强化学习等技术,提高了识别精度和上下文理解能力。在视频、直播和会议等,在多人交谈或背景噪音中也能准确转录,错误率比现有大型ASR模型降低10%-40%。Seed-ASR的上下文感知能力使其在智能助手和语音搜索等应用场景中效果更佳。
Seed-ASR的主要功能
高精度语音识别:能准确识别和转录多种语言、方言和口音的语音信号。多语言支持:支持普通话、英语及其他多种语言,具备扩展至超过40种语言的能力。上下文感知:利用历史对话、视频编辑历史等上下文信息,提高关键词识别和转录的准确性。大规模训练:基于大量语音数据进行训练,增强模型的泛化能力。分阶段训练策略:通过自监督学习、监督微调、上下文微调和强化学习等阶段,逐步提升模型性能。长语音处理:有效处理长语音输入,保持信息的完整性和转录的准确性。Seed-ASR的技术原理
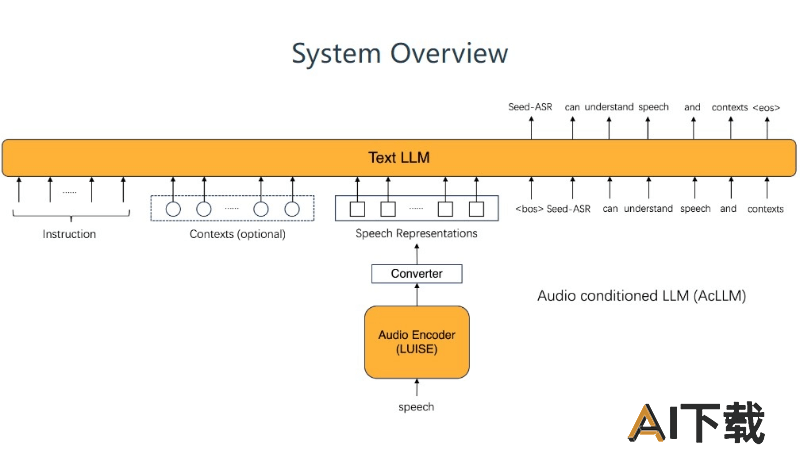
大型语言模型(LLM)基础:Seed-ASR构建在大型语言模型之上,基于强大的文本理解和生成能力。音频条件的语言模型(AcLLM)框架:框架通过输入连续的语音表示和上下文信息到预训练的LLM中,模型能理解语音内容并生成相应的文本。自监督学习(SSL):在没有标签的大规模语音数据上进行训练,音频编码器能捕捉丰富的语音特征。监督微调(SFT):在SSL阶段之后,使用大量语音-文本对进行训练,建立语音到文本的映射。上下文感知训练:通过引入上下文信息(如历史对话、视频编辑历史等)进行训练,提高模型在特定上下文中的识别能力。强化学习(RL):使用基于ASR性能指标的奖励函数,进一步优化模型的文本生成行为,特别是对于语义重要部分的准确转录。