HeadGAP是什么
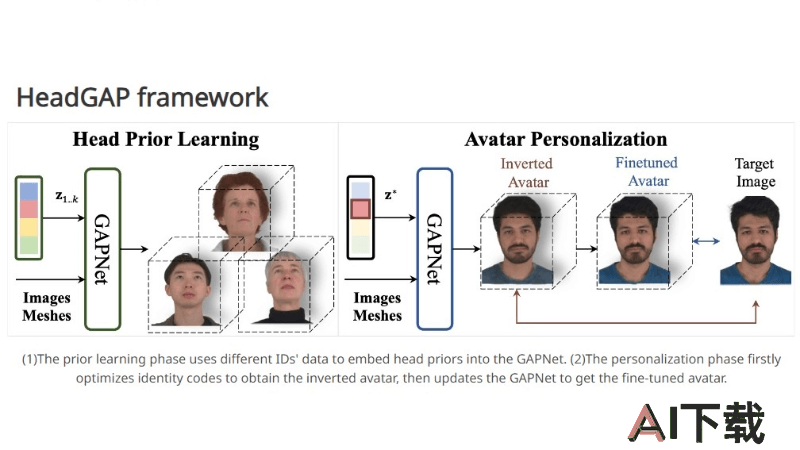
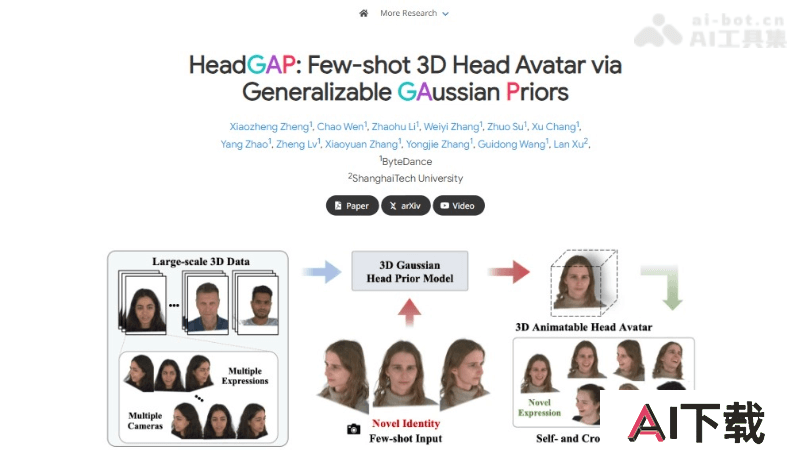
HeadGAP是字节跳动和上海科技大学共同推出的3D头像生成模型,仅用少量图片快速生成逼真的3D头像。采用先验学习和个性化创建阶段的框架,基于大规模多视角动态数据集导出的3D头部先验信息。通过高斯Splatting自动解码网络和部分动态建模,结合身份共享编码与个性化潜在代码,HeadGAP实现了高保真度和可动画的3D头像,具有多视图一致性和稳定动画效果。
HeadGAP的主要功能
少样本学习:能从极少量的图片(甚至只有一张)中创建出逼真的3D头像。高保真度:生成的3D头像具有照片级的渲染质量,细节丰富且真实。动画鲁棒性:头像不仅在视觉上逼真,还能进行流畅的动画表现,适应不同的面部表情和动作。个性化定制:通过先验学习和个性化阶段,能够根据用户的具体特征进行定制化处理。多视角一致性:头像在不同视角下都能保持一致性,无论是正面、侧面还是斜视等。HeadGAP的技术原理
先验学习阶段:在这个阶段,系统通过分析大规模多视角动态数据集中的3D头部模型,学习并提取头部的通用特征和形状先验。高斯Splatting网络:基于高斯分布的自动解码器网络,能将3D头部数据分布表示为高斯原语的集合,捕捉头部的复杂几何结构。身份共享编码与个性化潜在代码:采用共享编码来学习不同身份之间的共同特征,同时为每个个体生成个性化的潜在代码,以学习个体独特的属性。部分动态建模:通过基于部件的建模方法,能对头像的各个部分进行动态调整,适应不同的面部表情和动作。