LMMs-Eval是什么
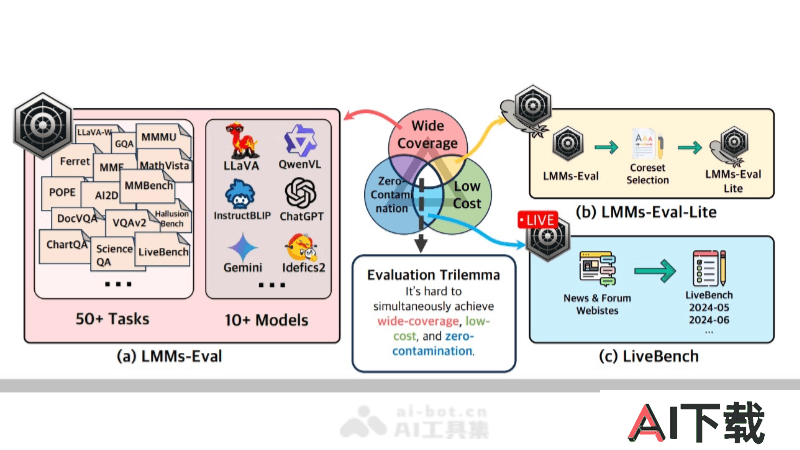
LMMs-Eval 是一个专为多模态AI模型设计的统一评估框架,提供标准化、广泛覆盖且成本效益高的模型性能评估解决方案。包含超过50个任务和10多个模型,通过透明和可复现的评估流程,帮助研究者和开发者全面理解模型能力。LMMs-Eval 还引入了 LMMs-Eval Lite 和 LiveBench,前者通过精简数据集降低评估成本,后者用最新网络信息进行动态评估,以零污染的方式考察模型的泛化能力。为多模态模型的未来发展提供了重要的评估工具。

LMMs-Eval的主要功能
统一评估套件:提供标准化的评估流程,支持对超过50个任务和10多个模型的多模态能力进行综合性评估。透明可复现:确保评估结果的透明度和可复现性,便于研究者验证和比较不同模型的性能。广泛覆盖:涵盖多种任务类型,如图像理解、视觉问答、文档分析等,全面考察模型的多模态处理能力。低成本评估:通过 LMMs-Eval Lite 提供精简的评估工具包,减少数据集规模,降低评估成本,同时保持评估质量。LMMs-Eval的技术原理
标准化评估流程:定义统一的接口和评估协议,LMMs-Eval 允许研究者在相同的基准上测试和比较不同模型性能。多任务评估:框架设计为可以同时处理多种类型的任务,包括但不限于图像和语言的理解和生成任务。数据集选择与核心集(Coreset)提取:LMMs-Eval 用算法选择代表性数据子集,以减少评估所需的资源,同时保持评估结果的一致性和可靠性。动态数据收集:LiveBench 组件通过从互联网上的新闻和论坛自动收集最新信息,生成动态更新的评估数据集。防污染机制:通过分析训练数据和评估基准数据之间的重叠,LMMs-Eval 能识别和减少数据污染,确保评估的有效性。