GLM-4V-Plus是什么
GLM-4V-Plus是智谱AI最新推出的多模态AI模型,专注于图像和视频理解。GLM-4V-Plus不仅能够精确分析静态图像,还具备动态视频内容的时间感知和理解能力,能捕捉视频中的关键事件和动作。作为国内首个提供视频理解API的模型,GLM-4V-Plus已集成在“智谱清言APP”中,并上线“视频通话”功能。同时,GLM-4V-Plus在智谱AI开放平台 BigModel 上同步开放API,支持开发者和企业用户快速集成视频分析功能,广泛应用于安防监控、内容审核、智能教育等多个场景。

GLM-4V-Plus的功能特色
多模态理解:结合了图像和视频理解能力,能轻松处理和分析视觉数据。高质量图像分析:具备卓越的图像识别和分析能力,能够理解图像内容。视频内容理解:能解析视频内容,识别视频中的对象、动作和事件。时间感知能力:对视频内容具备时间序列的理解,能够捕捉视频中随时间变化的信息。API服务:作为国内首个通用视频理解模型API,GLM-4V-Plus提供开放平台服务,易于集成。实时交互:支持实时视频分析和交互,适用于需要快速响应的应用场景。如何使用GLM-4V-Plus
产品体验:GLM-4V-Plus已集成至 智谱清言 ,可以直接在清言APP中体验。API接入:GLM-4V-Plus已开放API,可以通过 智谱AI开放平台 BigModel 中接入使用。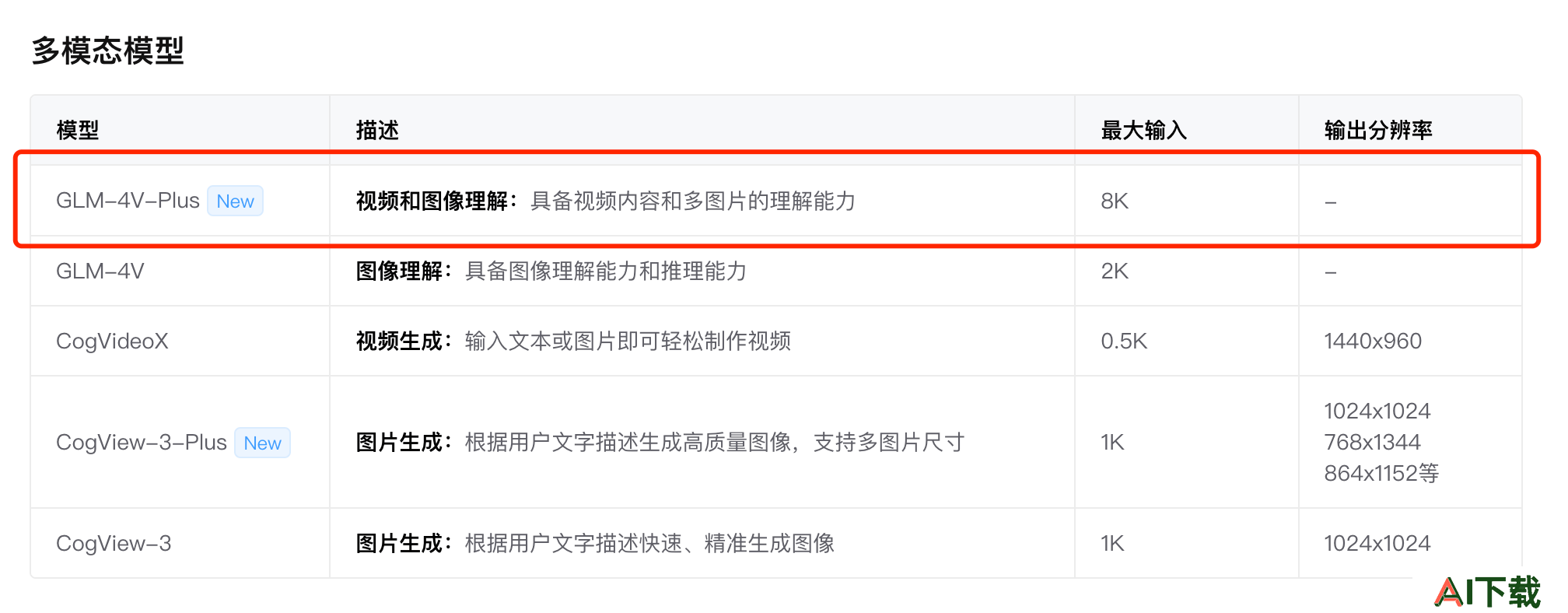
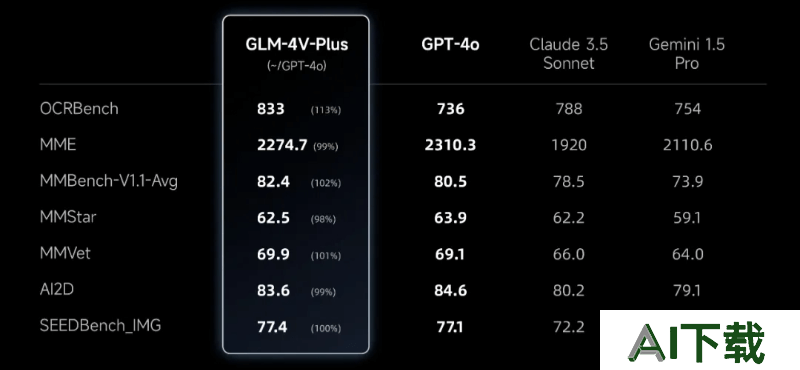
GLM-4V-Plus的性能指标
具备高质量图像理解和视频理解能力的多模态模型 GLM-4V-Plus,性能指标接近GPT-4o。