DeepSeek V3是什么
DeepSeek V3是知名私募巨头幻方量化旗下人工智能公司深度求索(DeepSeek)开源的最新版AI模型,在多语言编程能力上的进步显著。在aider多语言编程测评中的表现超越了Claude 3.5 Sonnet V2等竞争对手。DeepSeek V3采用了高达6850亿参数的混合专家(MoE)架构,包含256个专家,使用sigmoid路由方式,每次选取前8个专家参与计算,模型能更高效地处理复杂任务。V3模型提升了响应速度和处理效率,DeepSeek-V3 的生成吐字速度从 20 TPS 大幅提高至 60 TPS,相比 V2.5 模型实现了 3 倍的提升,在处理多模态数据和长文本时表现突出。DeepSeek V3已经开源,可以在Hugging Face上查看。

DeepSeek V3的主要功能
自然语言查询处理:DeepSeek V3能理解和处理用户的自然语言查询,提供快速准确的回答。代码生成能力:产品具备代码生成功能,可以帮助开发者快速生成代码片段,提高开发效率。训练效率:支持 FP8 混合精度训练,提高训练速度,减少 GPU 内存使用。设计 DualPipe 算法,实现高效的流水线并行处理。优化跨节点 All-to-All 通信,充分利用 InfiniBand 和 NVLink 带宽。预训练和后训练:在 14.8T tokens 上进行预训练,通过两阶段上下文扩展,将上下文窗口从 4K 扩展到 128K。进行监督式微调和强化学习,符合人类偏好并进一步释放潜力。性能评估:在多个标准和开放式基准测试中,DeepSeek-V3 的基础模型表现出色,尤其在代码和数学领域。聊天版本的 DeepSeek-V3 也超越了其他开源模型,并与领先的闭源模型性能相当。成本效益:训练成本仅为 2.788M H800 GPU 小时,总成本为 5.576M 美元。API和Web服务:DeepSeek提供API和Web服务,方便用户在不同场景下集成和使用。多语言处理能力:DeepSeek V3在多语言编程能力上取得了重大突破,在aider多语言编程测评中的表现超越了Claude3.5 Sonnet V2等竞争对手。DeepSeek V3的技术原理
架构设计:DeepSeek V3采用了混合专家(Mixture-of-Experts, MoE)架构,架构包含多达256个专家,每个专家都是一个独立的神经网络,能处理特定的任务或数据类型。在MoE架构中,不是所有的专家都会参与到每一次的计算中,而是通过一种路由机制(如sigmoid路由方式)动态选择一部分专家进行计算。在DeepSeek V3中,每次计算会选取前8个最相关的专家(topk=8)参与。工作机制:分为以下几个关键阶段:计划:基于用户查询,规划最终结果的形式,定义要提取的实体类型及相关的列。搜索:结合关键词搜索与神经搜索,在Exa的支持下,精准定位内容。提取:利用大型语言模型(LLM),高效识别并提取内容中的特定信息。丰富:对提取的数据进行进一步的内容填充,确保每个条目详尽无遗。多模态能力:DeepSeek V3使用OCRvl2技术,能更好地保留图片中的文字、格式排版和公式,效果超越传统OCR。流式渲染优化:网页端采用流式输出,但由于每次渲染需要重新解析Markdown,当前60tps渲染速度可能会导致一定的延迟。DeepSeek V3的项目地址
HuggingFace模型库:https://huggingface.co/collections/deepseek-ai/deepseek-v3论文链接:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdfDeepSeek V3的性能和效率提升
参数规模:DeepSeek V3采用了高达6850亿参数的MoE架构,这种大规模参数化使得模型能够捕捉更复杂的模式和关系。计算资源管理:通过MoE架构,DeepSeek V3能够动态选择最合适的专家进行计算,从而减少不必要的计算和内存消耗。数据并行和模型并行:DeepSeek V3在训练过程中使用了数据并行、张量并行、序列并行和1F1B流水线并行等并行策略,这些策略提高了硬件利用率,加快了模型的训练速度。优化的学习率调度器:DeepSeek V3使用了多阶段学习率调度器,这有助于模型在不同的训练阶段保持最佳的学习速率。Scaling Laws研究:DeepSeek V3的开发团队对Scaling Laws进行了深入研究,以找到最优的模型/数据规模分配比例,并对大规模模型训练结果进行预测。安全评估:DeepSeek V3在全训练过程中都进行严格的数据安全性筛选,确保训练得到的模型是符合人类价值观的。DeepSeek V3 的多项评测成绩
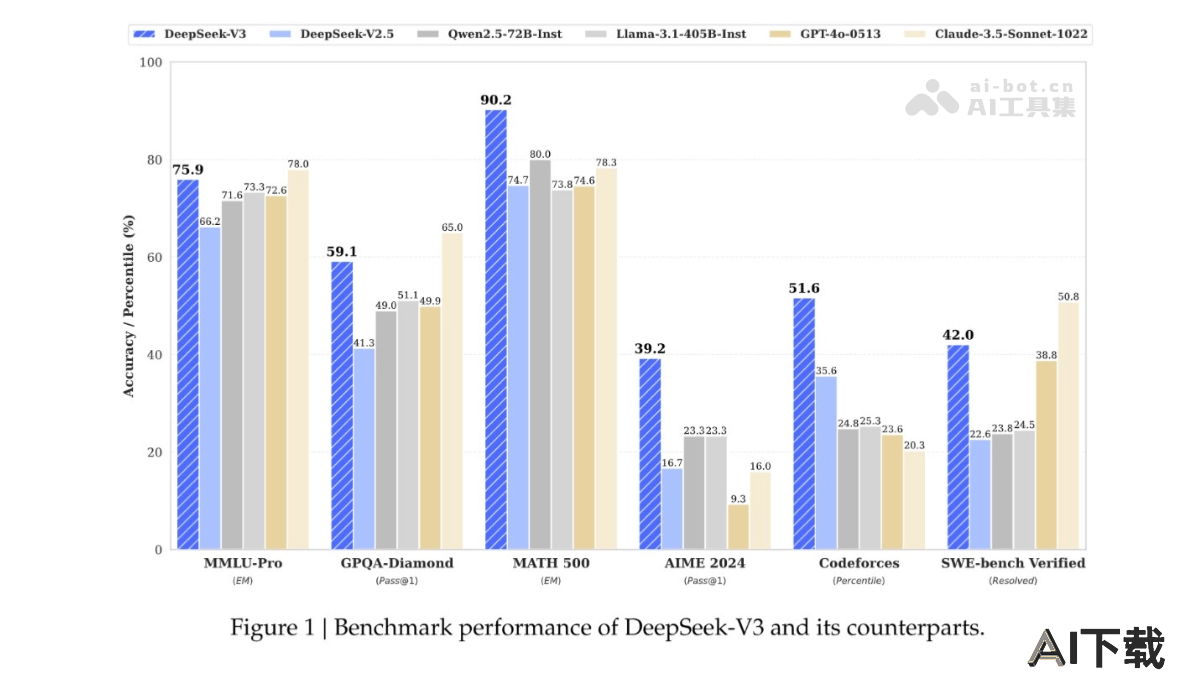
在LiveBench测试中:DeepSeek V3的得分非常高,表明能快速响应用户的查询并提供反馈。全球平均分:60.4分推理能力:50分编程技能:63.4分数学解析:60分数据分析:57.7分语言理解:50.2分即时反馈(IF):80.9分教育基准测试:在 MMLU(多主题多选题)基准测试中,DeepSeek-V3 取得了 88.5% 的准确率,超越了其他所有开源模型,与领先的闭源模型如 GPT-4o 和 Claude-Sonnet-3.5 相当。在 MMLU-Pro(更严格的多主题多选题)中,DeepSeek-V3 取得了 75.9% 的准确率,同样领先于其他开源模型,并与顶级闭源模型性能相当。事实性基准测试:在 SimpleQA(简单问答)和 Chinese SimpleQA(中文简单问答)中,DeepSeek-V3 在中文事实性知识方面超过了 GPT-4o 和 Claude-Sonnet-3.5,显示出其在中文事实性知识方面的优势。代码、数学和推理基准测试:DeepSeek-V3 在所有非长链推理(non-long-CoT)的开源和闭源模型中,在数学相关基准测试中表现最佳,甚至在某些基准测试中超过了 o1-preview,如 MATH-500,显示出其强大的数学推理能力。在编程相关任务中,DeepSeek-V3 在 LiveCodeBench(实时代码基准测试)中成为表现最好的模型,巩固了其在这一领域的领先地位。开放式评估:在开放式对话评估中,DeepSeek-V3 在 AlpacaEval 2.0 和 Arena-Hard 基准测试中取得了优异的成绩,显示出其在处理复杂提示和任务时的强大能力。作为生成性奖励模型的评估:在 RewardBench 评估中,DeepSeek-V3 显示出与 GPT-4o 和 Claude-3.5 相当的性能,进一步证明了其作为奖励模型的判断能力。