DeepGEMM是什么
DeepGEMM是DeepSeek开源的为高效简洁的FP8矩阵乘法(GEMM)设计的库,目前仅支持NVIDIA Hopper张量核心。DeepGEMM支持普通和混合专家(MoE)分组的GEMM操作,基于即时编译(JIT)技术,无需安装时编译,支持在运行时动态优化。DeepGEMM基于细粒度缩放和CUDA核心双级累加技术,解决FP8精度不足的问题,同时用Hopper的Tensor Memory Accelerator(TMA)特性提升数据传输效率。DeepGEMM核心代码仅约300行,易于学习和优化。DeepGEMM的轻量设计,在多种矩阵形状上均达到或超过专家级优化库。

DeepGEMM的主要功能
高效FP8矩阵乘法(GEMM):DeepGEMM是专为FP8(8位浮点)矩阵乘法设计的高效库,支持细粒度缩放,显著提升矩阵运算的性能和精度。支持普通和分组GEMM:普通GEMM:适用于常规的矩阵乘法操作。分组GEMM:支持混合专家(MoE)模型中的分组矩阵乘法,包括连续布局(contiguous layout)和掩码布局(masked layout),优化多专家共享形状的场景。即时编译(JIT)设计:基于即时编译技术,所有内核在运行时动态编译,无需安装时编译。根据矩阵形状、块大小等参数进行优化,节省寄存器提升性能。Hopper架构优化:专为NVIDIA Hopper架构设计,充分利用Tensor Memory Accelerator(TMA)特性,包括TMA加载、存储、多播和描述符预取,显著提升数据传输效率。细粒度缩放和双级累加:为解决FP8精度不足的问题,DeepGEMM引入细粒度缩放技术,基于CUDA核心的双级累加机制,将FP8计算结果提升到更高精度的格式(如BF16),确保计算精度。轻量级设计:核心代码简洁,仅约300行,易于理解和扩展。避免复杂模板或代数结构的依赖,降低学习和优化的难度。DeepGEMM的项目地址
GitHub仓库:https://github.com/deepseek-ai/DeepGEMMDeepGEMM的性能表现
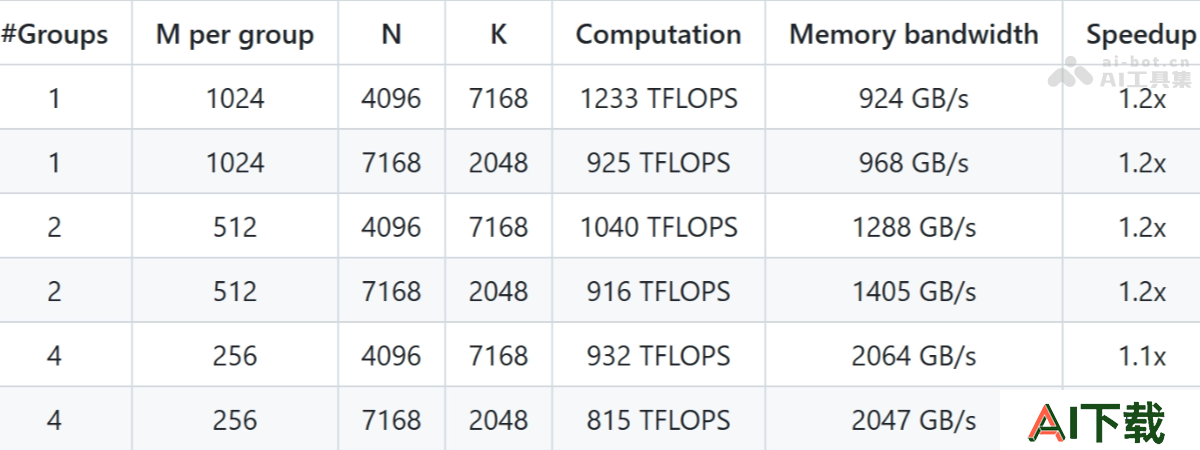
普通GEMM(非分组)性能最高加速比:在某些矩阵形状下,DeepGEMM能达到2.7倍的加速比,显著提升矩阵乘法的效率。计算性能:在大规模矩阵运算中,DeepGEMM能够实现超过1000 TFLOPS的计算性能,接近Hopper架构GPU的理论峰值。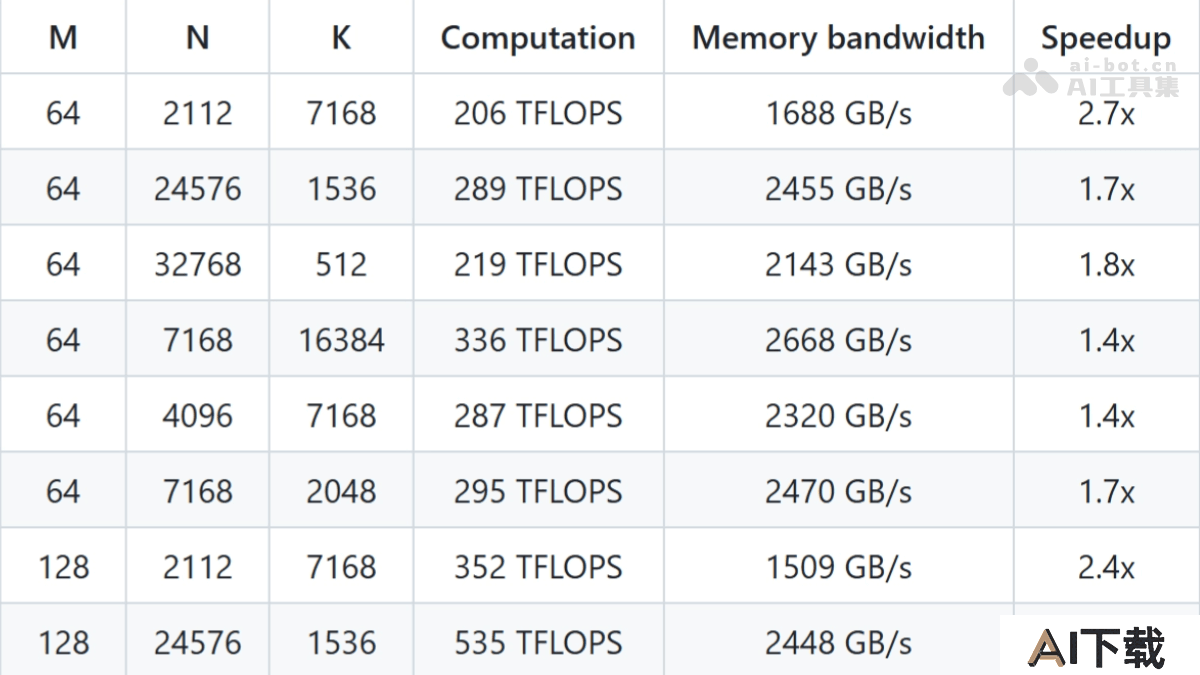 分组GEMM(MoE模型)性能加速比:在分组GEMM中,DeepGEMM能实现1.1-1.2倍的加速比,显著提升MoE模型的训练和推理效率。内存带宽优化:基于TMA特性,DeepGEMM在内存带宽利用上表现出色,达到接近硬件极限的性能。连续布局(Contiguous Layout)
分组GEMM(MoE模型)性能加速比:在分组GEMM中,DeepGEMM能实现1.1-1.2倍的加速比,显著提升MoE模型的训练和推理效率。内存带宽优化:基于TMA特性,DeepGEMM在内存带宽利用上表现出色,达到接近硬件极限的性能。连续布局(Contiguous Layout)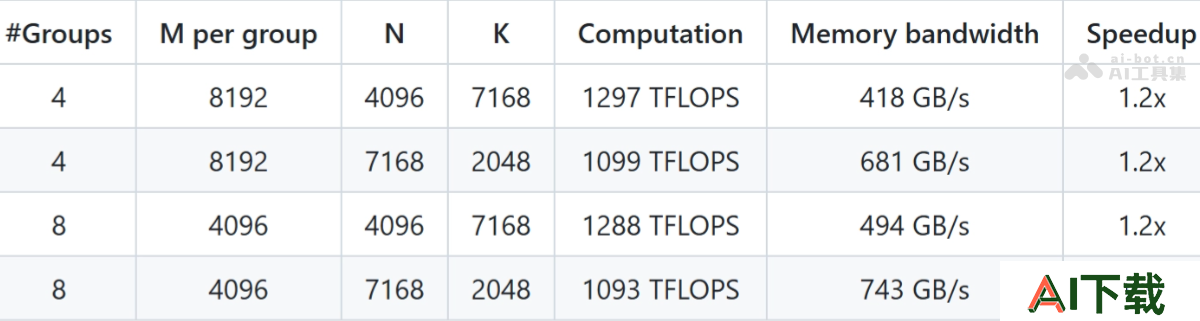 掩码布局(Masked Layout)
掩码布局(Masked Layout)