腾讯混元Turbo S是什么
腾讯混元Turbo S是腾讯推出的新一代快思考模型。模型采用创新的Hybrid-Mamba-Transformer融合架构,有效降低了传统Transformer的计算复杂度,减少了KV-Cache缓存占用,显著提升了训练和推理效率。作为业界首次将Mamba架构无损应用于超大型MoE模型的实践,Turbo S在知识、数学、推理等多个领域表现出色,与DeepSeek V3、GPT-4o等领先模型相当。
混元Turbo S的核心优势在于快速响应,能实现“秒回”,吐字速度提升一倍,首字时延降低44%。在短思维链任务(如数学、代码、逻辑推理)中表现优异,同时结合了混元T1慢思考模型的长思维链能力,兼顾稳定性和准确性。

腾讯混元Turbo S的主要功能
快速响应能力:混元Turbo S能实现“秒回”,吐字速度提升一倍,首字时延降低44%,显著提升了交互的流畅性和用户体验。多领域知识与推理能力:在知识、数理、逻辑推理等多个领域表现出色,对标DeepSeek V3、GPT-4o等业界领先模型。内容创作与多模态支持:支持高质量的文学创作、文本摘要、多轮对话等功能,同时具备文字生成图像的多模态能力。低部署成本与高性价比:采用Hybrid-Mamba-Transformer融合架构,降低了传统Transformer的计算复杂度和部署成本。腾讯混元Turbo S的技术原理
Mamba架构的优势:Mamba架构基于状态空间模型(State Space Model, SSM),通过引入选择性机制(Selective Mechanism),能高效处理长序列数据。在处理长文本时表现出色,同时显著降低了计算复杂度和KV-Cache缓存占用。Transformer架构的保留:Transformer架构擅长捕捉复杂的上下文关系,混元Turbo S保留了这一优势,同时通过融合Mamba架构,突破了传统Transformer在长文本处理和推理成本上的瓶颈。MoE模型的优化:混元Turbo S是工业界首次成功将Mamba架构无损地应用在超大型MoE(Mixture of Experts)模型上。提升了模型的显存和计算效率,降低了训练和推理成本。长短思维链融合:在保持文科类问题的快速响应(快思考)体验的同时,混元Turbo S通过自研的长思维链数据,显著改进了理科推理能力,实现了模型整体性能的提升。腾讯混元Turbo S的性能表现
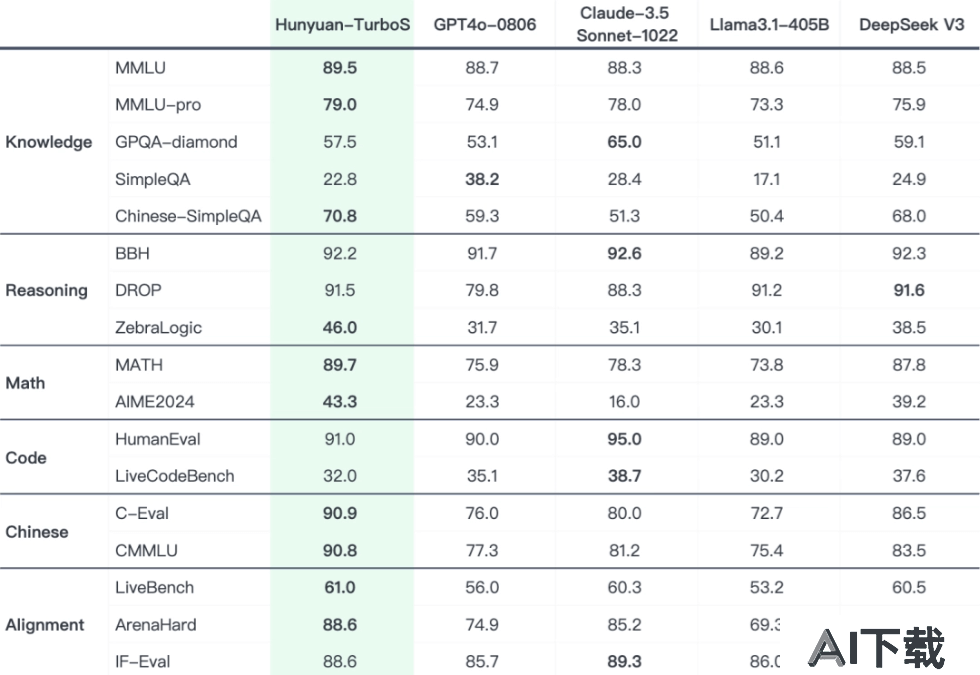
知识领域:在MMLU基准测试中,混元Turbo S得分为89.5,略低于DeepSeek V3的88.5,但高于其他模型。在MMLU-pro测试中,混元Turbo S得分为79.0,表现优于GPT4o-0806和Claude-3.5。在GPQA-diamond测试中,混元Turbo S得分为57.5,表现优于Llama3.1-405B和DeepSeek V3。在SimpleQA测试中,混元Turbo S得分为22.8,表现不如其他模型。在Chinese-SimpleQA测试中,混元Turbo S得分为70.8,表现优于GPT4o-0806和Claude-3.5。推理领域:在BBH测试中,混元Turbo S得分为92.2,表现优于其他所有模型。在DROP测试中,混元Turbo S得分为91.5,表现优于GPT4o-0806和Claude-3.5。在ZebraLogic测试中,混元Turbo S得分为46.0,表现不如其他模型。数学领域:在MATH测试中,混元Turbo S得分为89.7,表现优于GPT4o-0806和Claude-3.5。在AIME2024测试中,混元Turbo S得分为43.3,表现优于GPT4o-0806和Claude-3.5。代码领域:在HumanEval测试中,混元Turbo S得分为91.0,表现优于GPT4o-0806和Claude-3.5。在LiveCodeBench测试中,混元Turbo S得分为32.0,表现不如其他模型。中文领域:在C-Eval测试中,混元Turbo S得分为90.9,表现优于GPT4o-0806和Claude-3.5。在CMMLU测试中,混元Turbo S得分为90.8,表现优于GPT4o-0806和Claude-3.5。对齐领域:在ArenaHard测试中,混元Turbo S得分为88.6,表现优于GPT4o-0806和Claude-3.5。在IF-Eval测试中,混元Turbo S得分为88.6,表现优于GPT4o-0806和Claude-3.5。